Kubernetes 监控架构(译)
概要
监控分为两个部分:
- 核心监控流程由kubelet、资源评估器、metric-server(Heapster 精简版)以及API server 上的master metrics API 组成. 这些监控数据被系统核心组件使用,例如调度逻辑(调度器和基于系统指标的HPA) 和 开箱即用的UI组件(例如 kubectl top), 这条监控管道不适合与第三方监控系统集成.
- 另一个监控流程用于从系统收集各种指标并将这些指标导出到用户端、HPA(自定义指标)以及通过适配器到处到 infrastore. 用户可以从众多的监控系统中进行选择,也可以不运行监控系统. Kubernetes 不附带监控管道, 但是第三方的选项是很容易被安装的. 我们希望第三方管道通常由每个节点的代理和一个集群级聚合器组成.
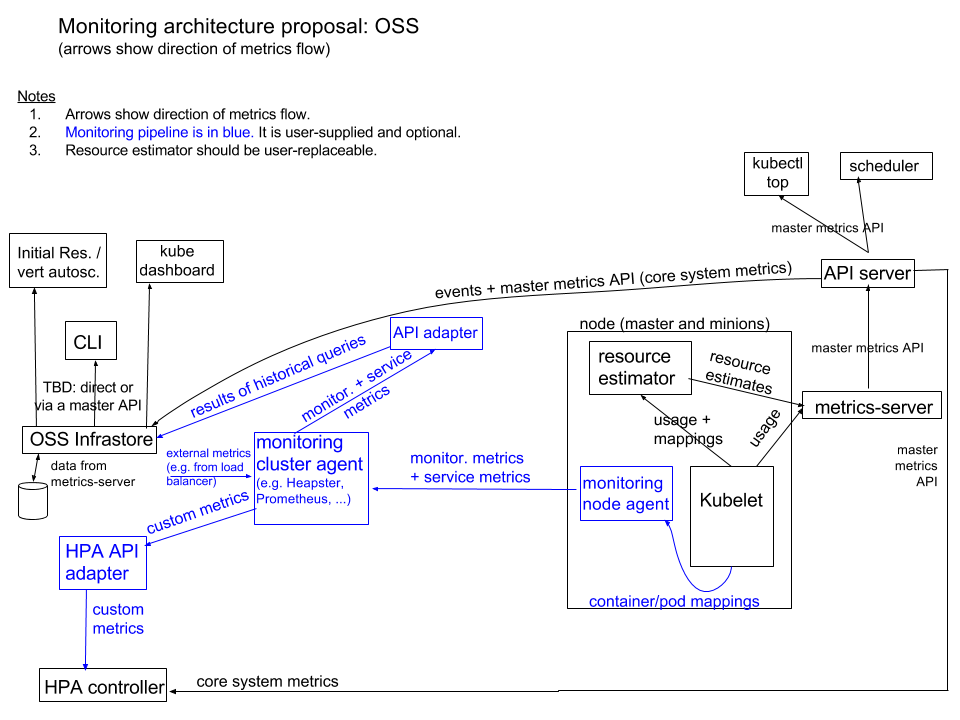
该架构在本文档附录中的图表中进行了说明。
介绍和目标
本文档为Kubernetes 提出了一个高级监控架构. 它涵盖了 Kubernetes Monitoring Architecture 文档中提到的一些问题. 特别关注有望满足大量需求的监控架构(组件以及组件之间的交互), 我们没有为实现这个架构指定任何特定的时间,也没有规划路线图.
术语
有两种指标系统指标和服务指标, 系统指标是一般的指标,通常可以从每个监控的实体获得(例如容器和节点的CPU和内存使用情况). 服务指标是在应用代码明确定义并导出的(例如API服务器状态码为500的请求数量), 系统指标和服务指标都是从用户的容器或者系统基础组件获取(主节点组件,比如API服务器, 运行在主节点的插件pod, 和运行在用户节点的插件pod)
我们把系统指标分为:
- 核心指标 这些指标都是Kubernetes理解并用于其内部组件和核心业务的指标 — 例如, 用于调度的指标(包括用于资源评估、初始资源/垂直自动缩放,集群自动缩放, 和Pod水平自动缩放(不包括自定义指标)), Kube 仪表盘, 和 “kubectl top”, 截至目前, 这包括cpu 累计使用情况, 内存瞬时使用情况, pod 磁盘使用情况, 容器的磁盘使用情况.
- 非核心指标,不被 Kubernetes 解读;我们通常假设它们包括核心指标(尽管不一定采用 Kubernetes 理解的格式)以及其他指标。 我们认为日志记录与监控是分开的,因此日志记录超出了本文档的范围。
要求
监控架构应该是下面这个样子:
- 包括作为核心 Kubernetes 一部分的解决方案和
- 通过标准的主 API(今天的主指标 API)使有关节点、Pod 和容器的核心系统指标可用,从而使 Kubernetes 的核心功能不依赖于非核心组件
- 要求 Kubelet 仅导出一组有限的指标,即核心 Kubernetes 组件正确运行所需的指标(这与#18770相关)
- 可以扩展到至少 5000 个节点
- 足够小,我们可以要求它的所有组件在所有部署配置中运行
- 包括一个可以提供历史数据的开箱即用的解决方案,例如支持初始资源和垂直 pod 自动缩放以及集群分析查询,这仅依赖于核心 Kubernetes
- 允许不属于核心 Kubernetes 的第三方监控解决方案,并且可以与需要服务指标的 Horizontal Pod Autoscaler 等组件集成
架构
我们将长期架构计划的描述分为核心指标管道和监控管道。对于每个,有必要考虑如何处理来自 master 和 minion 的每种类型的指标(核心指标、非核心指标和服务指标)
核心指标管道
核心指标管道收集一组核心系统指标。这些指标有两个来源
- Kubelet,提供每个节点/pod/容器的使用信息(目前属于 Kubelet 一部分的 cAdvisor 将被精简以仅提供核心系统指标)
- 作为 DaemonSet 运行的资源估计器,将从 Kubelet 中获取的原始使用值转换为资源估计值(调度程序使用的值用于更高级的基于使用情况的调度程序) 这些来源由我们称为metrics-server的组件抓取,它类似于当今 Heapster 的精简版。metrics-server 仅在本地存储最新值并且没有接收器。metrics-server 公开主指标 API。(此处描述的配置类似于当前"独立"模式下的 Heapster。) 发现汇总器使主指标 API 可用于外部客户端,因此从客户端的角度来看,它看起来与访问 API 服务器相同。
核心(系统)指标在所有部署环境中都按上述方式处理。唯一容易替换的部分是资源估计器,理论上,它可以由高级用户替换。metric-server 本身也可以被替换,但它类似于替换 apiserver 本身或可能与替换controller-manager类似,但不推荐也不支持。
最终,核心指标管道也可能从 Kubelet 和 Docker 守护进程本身收集指标(例如 Kubelet 的 CPU 使用率),即使它们不在容器中运行。
核心指标管道故意很小,并非为第三方集成而设计。"成熟的"监控留给第三方系统,它们提供监控管道(见下一节)并且可以在 Kubernetes 上运行,而无需对上游组件进行更改。通过这种方式,我们可以消除今天的负担,即维护 Heapster 作为每个可能的指标源、接收器和功能的集成点。
基础设施
我们将构建一个开源 Infrastore 组件(最有可能重用现有技术),为核心系统指标和事件的历史查询提供服务,它将从主 API 中获取。Infrastore 将公开一个或多个 API(可能只是类似 SQL 的查询——这是待定的)来处理以下用例
- 初始资源
- 垂直自动缩放
- 旧定时器 API
- 用于调试、容量规划等的决策支持查询。
- Kubernetes 仪表板中的使用图表 此外,它可能会收集监控指标和服务指标(至少从 Kubernetes 基础设施容器中),在接下来的部分中进行了描述。
监控管道
如上一节所述,为核心指标构建专用指标管道的目标之一是允许单独的监控管道,该管道非常灵活,因为核心 Kubernetes 组件不需要依赖它。默认情况下,我们不会提供但我们会提供一种简单的安装方法(使用单个命令,最有可能使用 Helm)。我们在本节中描述了监控管道。
监控管道收集的数据可能包含以下指标组的任何子集或超集:
- 核心系统指标
- 非核心系统指标
- 来自用户应用程序容器的服务指标
- 来自 Kubernetes 基础设施容器的服务指标;这些指标使用 Prometheus 检测公开 由监控解决方案决定收集哪些数据。
为了支持基于自定义指标的HPA,监控管道的提供者还必须创建一个无状态 API 适配器,从监控管道中提取自定义指标并将它们公开给 HPA。此类 API 将是一个定义明确的版本化 API,类似于常规 API。该组件的详细设计文档将介绍如何公开或发现它的详细信息。
如果希望在 Infrastore 中提供监控管道指标,则应用相同的方法。这些适配器可以是独立的组件、库或监控解决方案本身的一部分。
有许多可能的节点和集群级代理组合可以构成监控管道,包括 cAdvisor + Heapster + InfluxDB(或任何其他接收器)
- cAdvisor + collectd + Heapster
- cAdvisor + Prometheus
- snapd + Heapster
- snapd + SNAP 集群级代理
- Sysdig 作为示例,我们将描述与 cAdvisor + Prometheus 的潜在集成。
Prometheus 在一个节点上有以下指标来源:
- 来自 cAdvisor 的核心和非核心系统指标
- 容器通过 Prometheus 格式的 HTTP 处理程序公开的服务指标
- [可选] 节点导出器(Prometheus 组件)中有关节点本身的指标 所有这些都由 Prometheus 集群级代理轮询。我们可以使用 Prometheus 集群级代理作为水平 pod 自动缩放自定义指标的来源,通过使用独立 API 适配器在 Prometheus 集群级代理上的 Prometheus 查询语言端点和特定于 HPA 的 API 之间进行代理/转换。同样,适配器可用于在 Infrastore 中提供来自监控管道的指标。如果用户不需要相应的功能,则不需要任何适配器。
安装 cAdvisor+Prometheus 的命令还应该自动设置从基础设施容器收集指标。这是可能的,因为基础设施容器的名称和感兴趣的指标是 Kubernetes 控制平面配置本身的一部分,并且因为基础设施容器以 Prometheus 格式导出它们的指标。
附录: 架构图