Karmada Scheduler核心实现

文章目录
Karmada(Kubernetes Armada) 是一个多集群管理系统,在原生 Kubernetes 的基础上增加对于多集群应用资源编排控制的API和组件,从而实现多集群的高级调度,本文就详细分析一下 karmada 层面多集群调度的具体实现逻辑。 Karmada Scheduler( Karmada 调度组件)主要是负责处理添加到队列中的 ResourceBinding 资源,通过内置的调度算法为资源选出一个或者多个合适的集群以及 replica 数量。
注意: 本文使用 karmada 版本为 tag:v0.8.0 commit: c37bedc1
调度框架
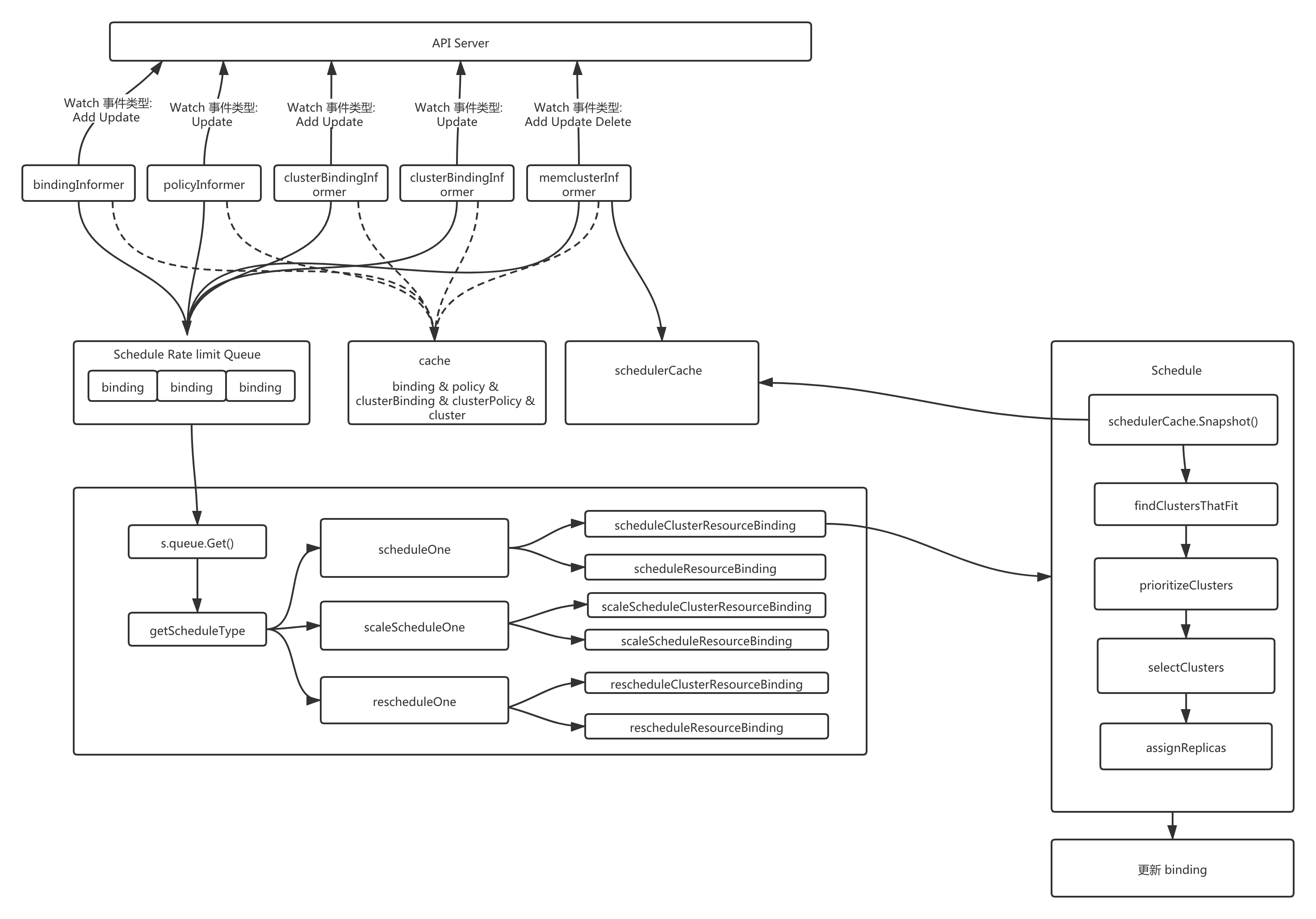
karmada-scheduler 在启动过程中实例化并运行了多个资源的 Informer(如图所示有bindingInformer, policyInformer,clusterBindingInformer, clusterPolicyInformer, memberClusterInformer)。
bindingInformer, clusterBindingInformer 是直接监听binding/clusterBinding 的Add/Update事件存储到调度队列;
policyInformer/clusterPolicyInformer 是用来监听 policy/clusterPolicy 的Update事件,将关联的 binding/clusterBinding 添加到调度队列;
memberClusterInformer 将监控到的 cluster 资源存储到调度缓存中。
- 调度队列: 存储了待处理的 binding/clusterBinding 事件,使用的是先进先出队列。
- 调度缓存: 缓存了 cluster 的信息。
需要根据 binding/clusterBinding 当前状态决定下一步如何处理,共有如下几个状态,以 binding 为例:
- 首次调度(FirstSchedule): resourceBinding 对象中的 spec.Clusters 字段为空,即从未被调度过。
- 调协调度(ReconcileSchedule): policy 的 placement 发生变化时就需要进行调协调度。
- 扩缩容调度(ScaleSchedule): policy ReplicaSchedulingStrategy 中 replica 与实际运行的不一致时就需需要进行扩缩容调度。
- 故障恢复调度(FailoverSchedule): 调度结果集合中 cluster 的状态如果有未就绪的就需要进行故障恢复调度。
- 无需调度(AvoidSchedule): 默认行为,上面四个调度都未执行,则不进行任何调度。
首次调度(FirstSchedule)
主要通过 scheduleOne 函数来实现,分为以下几个步骤:
- 根据 namespace 和 name 查询出 resource binding;
- 执行 预选算法 优选算法选择出合适的集群集合;
- 执行 优选算法 为选择出的集群进行打分(未实现);
- 为选择的集群分配Replicas;
- 更新结果到 binding 的 spec.Clusters 字段,并通过API接口更新存储;
预选算法
通过 findClustersThatFit 找到符合基本条件的集群;
代码路径 pkg/scheduler/core/generic_scheduler.go
1// findClustersThatFit finds the clusters that are fit for the placement based on running the filter plugins.
2func (g *genericScheduler) findClustersThatFit(
3 ctx context.Context,
4 fwk framework.Framework,
5 placement *policyv1alpha1.Placement,
6 resource *workv1alpha1.ObjectReference,
7 clusterInfo *cache.Snapshot) ([]*clusterv1alpha1.Cluster, error) {
8 var out []*clusterv1alpha1.Cluster
9 clusters := clusterInfo.GetReadyClusters()
10 for _, c := range clusters {
11 resMap := fwk.RunFilterPlugins(ctx, placement, resource, c.Cluster())
12 res := resMap.Merge()
13 if !res.IsSuccess() {
14 klog.V(4).Infof("cluster %q is not fit", c.Cluster().Name)
15 } else {
16 out = append(out, c.Cluster())
17 }
18 }
19
20 return out, nil
21}
通过 RunFilterPlugins 执行 filter 的扩展函数从而过滤掉不符合条件的集群, 扩展点包含三个插件:
- clusteraffinity: 集群亲缘性过滤,通过 ExcludeClusters 可以明确排除某些集群, 也可以通过 LabelSelector FieldSelector 进行匹配,也可以直接通过 cluster name 进行匹配;
- tainttoleration: 污点容忍性,过滤掉带有 tanit 但是 无法容忍的集群;
- apiinstalled: 检查资源的 API 是否已经安装,过滤掉未安装API的集群; 经过以上三步之后可以得到初步满足需求的集群集合。
优选调度过程
通过 预选调度 我们已经得到基本满足需求的集群集合,优选调度过程主要是通过策略给每个集群进行打分, 但是目前所有插件未实现具体逻辑,都简单返回0。 插件与预选过程是一样的,都是这以下三个插件:clusteraffinity、tainttoleration、apiinstalled。
选择集群过程
通过 预选调度 、 优选调度 我们可以得出符合条件的集群集合以及每个集群的得分(得分未实现),选择集群过程是通过 SpreadConstraint 定义的字段将集群划分成不同的组,尽量将资源分发到不同的组,从而实现高可用。 选择集群分为两步:
- 将集群按照类型划分成不同的组;
- 从不同的组中选择出合适的集群;
划分不同的组
SpreadConstraint 的类型有: cluster、region、zone、provider, 目前只支持 cluster。
1
2func (g *genericScheduler) selectClusters(clustersScore framework.ClusterScoreList, spreadConstraints []policyv1alpha1.SpreadConstraint, clusters []*clusterv1alpha1.Cluster) []*clusterv1alpha1.Cluster {
3 if len(spreadConstraints) != 0 {
4 return g.matchSpreadConstraints(clusters, spreadConstraints)
5 }
6
7 return clusters
8}
9func (g *genericScheduler) matchSpreadConstraints(clusters []*clusterv1alpha1.Cluster, spreadConstraints []policyv1alpha1.SpreadConstraint) []*clusterv1alpha1.Cluster {
10 state := util.NewSpreadGroup()
11 g.runSpreadConstraintsFilter(clusters, spreadConstraints, state)
12 return g.calSpreadResult(state)
13}
14
15// Now support spread by cluster. More rules will be implemented later.
16func (g *genericScheduler) runSpreadConstraintsFilter(clusters []*clusterv1alpha1.Cluster, spreadConstraints []policyv1alpha1.SpreadConstraint, spreadGroup *util.SpreadGroup) {
17 for _, spreadConstraint := range spreadConstraints {
18 spreadGroup.InitialGroupRecord(spreadConstraint)
19 if spreadConstraint.SpreadByField == policyv1alpha1.SpreadByFieldCluster {
20 g.groupByFieldCluster(clusters, spreadConstraint, spreadGroup)
21 }
22 }
23}
24
25func (g *genericScheduler) groupByFieldCluster(clusters []*clusterv1alpha1.Cluster, spreadConstraint policyv1alpha1.SpreadConstraint, spreadGroup *util.SpreadGroup) {
26 for _, cluster := range clusters {
27 clusterGroup := cluster.Name
28 spreadGroup.GroupRecord[spreadConstraint][clusterGroup] = append(spreadGroup.GroupRecord[spreadConstraint][clusterGroup], cluster)
29 }
30}
从不同的组选择出集群
1func (g *genericScheduler) chooseSpreadGroup(spreadGroup *util.SpreadGroup) []*clusterv1alpha1.Cluster {
2 var feasibleClusters []*clusterv1alpha1.Cluster
3 for spreadConstraint, clusterGroups := range spreadGroup.GroupRecord {
4 // 目前支持cluster name 进行的分组
5 if spreadConstraint.SpreadByField == policyv1alpha1.SpreadByFieldCluster {
6 // 如果小于最小组的数量,则返回nil
7 if len(clusterGroups) < spreadConstraint.MinGroups {
8 return nil
9 }
10 // 如果划分的组数 在最小-最大之间, 则将所有集群添加的结果集合
11 if len(clusterGroups) <= spreadConstraint.MaxGroups {
12 for _, v := range clusterGroups {
13 feasibleClusters = append(feasibleClusters, v...)
14 }
15 break
16 }
17 // 如果划分的组大于限制的最大组数,则将分组数限制为 MaxGroups
18 if spreadConstraint.MaxGroups > 0 && len(clusterGroups) > spreadConstraint.MaxGroups {
19 var groups []string
20 for group := range clusterGroups {
21 groups = append(groups, group)
22 }
23
24 for i := 0; i < spreadConstraint.MaxGroups; i++ {
25 feasibleClusters = append(feasibleClusters, clusterGroups[groups[i]]...)
26 }
27 }
28 }
29 }
30 return feasibleClusters
31}
为选择的集群分配Replicas
为选择的集群分配Replicas,是通过 assignReplicas 方法实现,该方法是根据 replicaSchedulingStrategy(在 propagation policy中定义 placement时,同时指定replica scheduling strategy) 策略进行分配。
1func (g *genericScheduler) assignReplicas(clusters []*clusterv1alpha1.Cluster, replicaSchedulingStrategy *policyv1alpha1.ReplicaSchedulingStrategy, object *workv1alpha1.ObjectReference) ([]workv1alpha1.TargetCluster, error) {
2 if len(clusters) == 0 {
3 return nil, fmt.Errorf("no clusters available to schedule")
4 }
5 targetClusters := make([]workv1alpha1.TargetCluster, len(clusters))
6
7 if object.Replicas > 0 && replicaSchedulingStrategy != nil {
8 if replicaSchedulingStrategy.ReplicaSchedulingType == policyv1alpha1.ReplicaSchedulingTypeDuplicated {
9 for i, cluster := range clusters {
10 targetClusters[i] = workv1alpha1.TargetCluster{Name: cluster.Name, Replicas: object.Replicas}
11 }
12 return targetClusters, nil
13 }
14 if replicaSchedulingStrategy.ReplicaSchedulingType == policyv1alpha1.ReplicaSchedulingTypeDivided {
15 if replicaSchedulingStrategy.ReplicaDivisionPreference == policyv1alpha1.ReplicaDivisionPreferenceWeighted {
16 if replicaSchedulingStrategy.WeightPreference == nil {
17 return nil, fmt.Errorf("no WeightPreference find to divide replicas")
18 }
19 return g.divideReplicasByStaticWeight(clusters, replicaSchedulingStrategy.WeightPreference.StaticWeightList, object.Replicas)
20 }
21 if replicaSchedulingStrategy.ReplicaDivisionPreference == policyv1alpha1.ReplicaDivisionPreferenceAggregated {
22 return g.divideReplicasAggregatedWithResource(clusters, object)
23 }
24 return g.divideReplicasAggregatedWithResource(clusters, object) //default policy for ReplicaSchedulingTypeDivided
25 }
26 }
27
28 for i, cluster := range clusters {
29 targetClusters[i] = workv1alpha1.TargetCluster{Name: cluster.Name}
30 }
31 return targetClusters, nil
32}
replica scheduler 支持两种类型的调度:
- 复制(ReplicaSchedulingTypeDuplicated): 不对 deployment 中的replica 数量做修改,直接复制到各个子集群;
- 切分(ReplicaSchedulingTypeDivided): 将 deployment 中定义的 replica数量,按照策略进行切分,然后分发到不同的子集群,目前支持的切分策略有: 权重(ReplicaDivisionPreferenceWeighted)、子集群资源(ReplicaDivisionPreferenceAggregated);
复制类型的调度很简单此处不展开介绍,我们重点介绍切分的不同策略:
按照权重进行切分
下面是按照权重划分的 策略定义, 特别注意的是,如果按照权重划分之后还有未分配的replica, 剩余的 replica 会按照顺序分配到各个集群(集群按照权重排序)上。
1apiVersion: policy.karmada.io/v1alpha1
2kind: ReplicaSchedulingPolicy
3metadata:
4 name: foo
5 namespace: foons
6spec:
7 resourceSelectors:
8 - apiVersion: apps/v1
9 kind: Deployment
10 namespace: foons
11 name: deployment-1
12 totalReplicas: 100
13 preferences:
14 staticWeightList:
15 - targetCluster:
16 clusterNames: [cluster1]
17 weight: 1
18 - targetCluster:
19 clusterNames: [cluster2]
20 weight: 2
按照子集群资源进行分配
如果 deployment 中资源的请求则按照子集群资源的使用情况进行分配,其核心逻辑如下所示:
- 计算每个子集群最大可以分配的replica;
- 按照比例分配replica;
计算每个子集群最大可以分配的replica
1func (g *genericScheduler) calClusterAvailableReplicas(cluster *clusterv1alpha1.Cluster, resourcePerReplicas corev1.ResourceList) int32 {
2 var maximumReplicas int64 = math.MaxInt32
3 resourceSummary := cluster.Status.ResourceSummary
4
5 for key, value := range resourcePerReplicas {
6 requestedQuantity := value.Value()
7 if requestedQuantity <= 0 {
8 continue
9 }
10
11 // calculates available resource quantity
12 // available = allocatable - allocated - allocating
13 allocatable, ok := resourceSummary.Allocatable[key]
14 if !ok {
15 return 0
16 }
17 allocated, ok := resourceSummary.Allocated[key]
18 if ok {
19 allocatable.Sub(allocated)
20 }
21 allocating, ok := resourceSummary.Allocating[key]
22 if ok {
23 allocatable.Sub(allocating)
24 }
25 availableQuantity := allocatable.Value()
26 // short path: no more resource left.
27 if availableQuantity <= 0 {
28 return 0
29 }
30
31 if key == corev1.ResourceCPU {
32 requestedQuantity = value.MilliValue()
33 availableQuantity = allocatable.MilliValue()
34 }
35
36 maximumReplicasForResource := availableQuantity / requestedQuantity
37 if maximumReplicasForResource < maximumReplicas {
38 maximumReplicas = maximumReplicasForResource
39 }
40 }
41
42 return int32(maximumReplicas)
43}
- 通过 available = allocatable - allocated - allocating 得到子集群目前可用资源;
- 通过如下计算得到该集群最大的replica:
1 maximumReplicasForResource := availableQuantity / requestedQuantity 2 if maximumReplicasForResource < maximumReplicas { 3 maximumReplicas = maximumReplicasForResource 4 }
按照比例分配replica
这块逻辑与权重分配类似,只不过这里的权重是 每个集群可以分配的最大replica. 其核心逻辑如下所示:
1func (g *genericScheduler) divideReplicasAggregatedWithClusterReplicas(clusterAvailableReplicas []workv1alpha1.TargetCluster, replicas int32) ([]workv1alpha1.TargetCluster, error) {
2 clustersNum := 0
3 clustersMaxReplicas := int32(0)
4 for _, clusterInfo := range clusterAvailableReplicas {
5 clustersNum++
6 clustersMaxReplicas += clusterInfo.Replicas
7 if clustersMaxReplicas >= replicas {
8 break
9 }
10 }
11 if clustersMaxReplicas < replicas {
12 return nil, fmt.Errorf("clusters resources are not enough to schedule, max %v replicas are support", clustersMaxReplicas)
13 }
14
15 desireReplicaInfos := make(map[string]int32)
16 allocatedReplicas := int32(0)
17 for i, clusterInfo := range clusterAvailableReplicas {
18 if i >= clustersNum {
19 desireReplicaInfos[clusterInfo.Name] = 0
20 continue
21 }
22 desireReplicaInfos[clusterInfo.Name] = clusterInfo.Replicas * replicas / clustersMaxReplicas
23 allocatedReplicas += desireReplicaInfos[clusterInfo.Name]
24 }
25
26 if remainReplicas := replicas - allocatedReplicas; remainReplicas > 0 {
27 for i := 0; remainReplicas > 0; i++ {
28 desireReplicaInfos[clusterAvailableReplicas[i].Name]++
29 remainReplicas--
30 if i == clustersNum {
31 i = 0
32 }
33 }
34 }
35
36 targetClusters := make([]workv1alpha1.TargetCluster, len(clusterAvailableReplicas))
37 i := 0
38 for key, value := range desireReplicaInfos {
39 targetClusters[i] = workv1alpha1.TargetCluster{Name: key, Replicas: value}
40 i++
41 }
42 return targetClusters, nil
43}
调协调度(ReconcileSchedule)
policy 的 placement 发生变化时就需要进行调协调度,与 首次调度 逻辑是一样的,都是通过函数 scheduleOne 来实现。
扩缩容调度(ScaleSchedule)
policy ReplicaSchedulingStrategy 中 replica 与实际运行的不一致时就需需要进行扩缩容调度。主要是通过 scaleScheduleOne 函数来实现,分为以下几个步骤:
- 根据 namespace 和 name 查询出 resource binding;
- 如果 指定的replica 大于0,则:
a.如果 ReplicaSchedulingType 为复制类型,则直接更新每个集群的replica;
b.如果 ReplicaSchedulingType 为切分并且定义了权重,则根据权重进行比例划分replica;
c.如果 ReplicaSchedulingType 为切分并且按照子集群资源切分,则根据子集群资源重新划分replica; - 如果没有定义 replica 则集群不指定replica;
- 更新结果到 binding 的 spec.Clusters 字段,并通过API接口更新存储;
故障恢复调度(FailoverSchedule)
调度结果集合中 cluster 的状态如果有未就绪的就需要进行故障恢复调度。主要通过 rescheduleOne 函数实现,分为以下几个步骤:
- 根据 namespace 和 name 查询出 resource binding;
- 获取所有就绪的集群 readyClusters ;
- 获取之前调度结果中的集群集合 totalClusters;
- 从 totalClusters 去掉未就绪的集群,得到调度集合中集群依然ready 的集群集合 reservedClusters;
- 获取就绪但是没有在之前调度结果集合中的集群,得到可用集群集合 availableClusters;
- 遍历 availableClusters ,过滤掉不满足基本要求(ClusterAffinity ClusterTolerations等)的集群,得到候选集群集合 candidateClusters;
- 如果候选集群的数量小于故障集群的数量,则终止调度;
- 从候选集群中选择与故障集群数量同等的集群,与 reservedClusters 组成最终结果;
- 更新结果到 binding 的 spec.Clusters 字段,并通过API接口更新存储;
总结
通过本文我们了解到了karmada调度器的核心实现逻辑:为resource binding选择合适的集群,并为根据不同的策略设置replica。